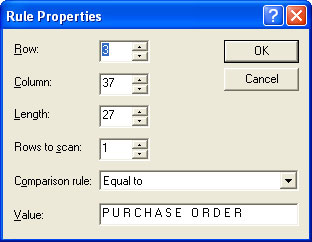
|
The identification rules in each entry are the
first to be tested by FTSplit when it receives a data
file. For each entry in the rule file, FTSplit
evaluates the identification rules and if the
identification rule is positive, FTSplit selects that
entry and uses its rules. Each entry MUST contain at
least ONE identification rule.
To create an identification rule:
- Select the Identification rule
button
 . .
- Highlight the text that will be used to identify
the document.
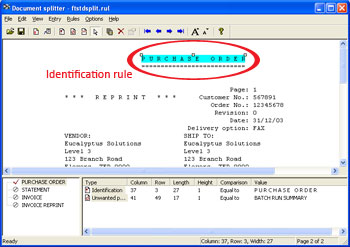
- The type of rule, its location and the text used
to evaluate the rule is then added to the rules
window.
A good place to find identification text is in the
heading of each document. In the above example the
heading P U R C H A S E O R D E R has been used.
You can create as many identification rules as are
needed to identify a document, and then choose whether FTSplit will match either all the identification rules,
or at least one, before identifying a document. It is
important to note that the identification rule is only
ever applied to the first two pages of the data file.
All pages following the second page are assumed to be of
the same type of document. This has implications if:
- The data used for the actual identification
appears later in the data; or
- Not all of the data file is of the same
document type.
To resolve either of these situations, it may be
necessary to produce multiple rule files and use the
queue redirection facilities in FTSpooler to correctly
split the entire data file appropriately. Visit
www.formtrap.com for more information.
|
 Overview
Overview Entry
Entry Rules
Rules