|
Once FTSplit has used the identification rules
to determine which entry in the rule file to use, it
uses the split and unwanted page rules in that entry to
split the batch run into individual documents and remove
any unwanted pages from the data file.
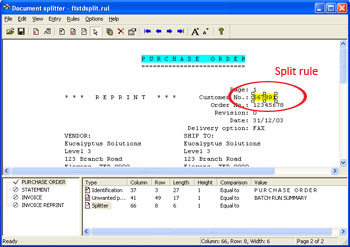
Like identification rules, split rules look for a
text string in a particular location on the page. For
greater flexibility split rules evaluate the text in two
different ways.
You can configure FTSplit to check if the string
MATCHES a specific value or to check if a string has
CHANGED value. When the split rule is evaluated as
positive, FTSplit determines that page to be the first
page of a new document.
To create a split rule:
|
 Overview
Overview Entry
Entry Rules
Rules