|
|
| Overview |
 |
|
The main purpose of FTSplit is to provide and implement rules
for identifying data as it is received by FTSpooler. Once
identified, data can be associated with a specific form or may
be redirected to another queue for further processing, typically
to be formatted using a different form. Such a need is common in
two
situations:
- where FormTrap is being used to process a large
number of varied documents, which would otherwise require the
creation of multiple FTSpooler queues; and
- where the file needs splitting into individual documents
that require individual delivery (email or fax).
Splitting involves two components:
FTSplitDef is the design
environment that allows you to create rules for identifying and
splitting batch runs; and FTSplit is the run time component
used by the FormTrap Spooler. FTSplit allows you to
identify data, split that data into separate documents according
to your user-defined rules as well as removing unwanted pages of data such as summary details from the
file.
|
|
FTSplit |
|
FTSplit operates according to three sets of
rules. For each type of data file you need to
define:
-
Identification rules - which identify the
Entire File as one type
of document.
-
Unwanted page rules (optional) - which identify
pages in the data stream that you do not want to
process.
-
Split rules
(optional) - which identify information that is used to split the
data file into individual
documents (e.g. change in document number or page
one).
When FTSplit receives a file, it
performs the following functions:
- FTSplit analyses the data file to
determine the type of document it is working with.
This is done for the first three pages only, if the
first of multiple entries does not succeed it looks at the second and so on.
- If the identified document has any unwanted page
rules, FTSplit removes all pages from
the data that match these rules before continuing.
- If the document type has rules for splitting,
then FTSplit begins writing data to file until
the first split rule succeeds. The file is then
closed and FTSplit begins writing a new file until
the split rule again succeeds. It does this until
all documents in a batch run have been re-written to
separate files according to the rules for splitting.
Note: Trying to split a SINGLE INPUT
FILE into two or more alternate outputs CANNOT BE DONE.
Each file is recognized ONCE ONLY, against ONE ONLY of
the entries.
See here for emailing (or faxing) individual documents. |
|
|
Top
|
|
FTSplitDef |
|
Using FTSplitDef, you
load a
sample data file and
create the rules to identify the data, remove unwanted
pages and split the data file into individual
documents. This information is saved into a rule file
for use with FTSplit.
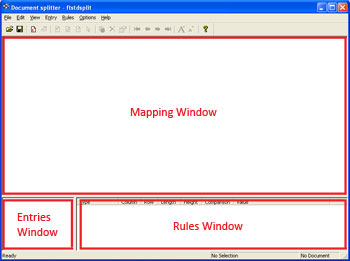
- Entries Window - contains a
list of the defined entries.
- Mapping Window - displays the
sample data file, onto which you can map the
rules.
- Rules Window - displays the
rules you have created for the selected entry.
|
|
|
Top
|
|
|
|
 Overview
Overview Entry
Entry